Введение
Помимо HTML, картинок и видео на сайте необходимо передавать и отображать различную информацию. Речь идет про массивы данных, про сложную иерархическую структуру. Для передачи информации как в интеграции, так и для сайтов используются определенные форматы данных. JSON и XML используются для получения и отправки данных с веб-сервера.
JSON
JSON(англ. JavaScript Object Notation) — простой формат обмена данными, основанный на языке программирования JavaScript. Использует человекочитаемый текст для передачи объектов данных.
Пример синтаксиса:
{
"squadName": "Super hero squad",
"homeTown": "Metro City",
"formed": 2016,
"secretBase": "Super tower",
"active": true,
"members": [
{
"name": "Molecule Man",
"age": 29,
"secretIdentity": "Dan Jukes",
"powers": [
"Radiation resistance",
"Turning tiny",
"Radiation blast"
]
},
{
"name": "Madame Uppercut",
"age": 39,
"secretIdentity": "Jane Wilson",
"powers": [
"Million tonne punch",
"Damage resistance",
"Superhuman reflexes"
]
},
{
"name": "Eternal Flame",
"age": 1000000,
"secretIdentity": "Unknown",
"powers": [
"Immortality",
"Heat Immunity",
"Inferno",
"Teleportation",
"Interdimensional travel"
]
}
]
}
Синтаксические правила JSON
- Данные указываются в парах имя / значение, разделяемые двоеточием «firstName»:«Lev»
- Данные разделяются запятыми «firstName»:«Anna», «lastName»: «Karenina»
- Фигурные скобки удерживают объекты {«firstName»:«Lev»,«lastName»:«Tolstoy»},
- Квадратные скобки содержат массивы
Преимущества JSON
- Меньше слов больше дела XML требует открытия и закрытия тегов, а JSON использует пары имя / значение, четко обозначенные «{«и»}» для объектов, «[«и»]» для массивов, «,» (запятую) для разделения пары и «:»(двоеточие) для отделения имени от значения.
- Размер имеет значение При одинаковом объеме информации JSON почти всегда значительно меньше, что приводит к более быстрой передаче и обработке.
- Близость к javascript JSON является подмножеством JavaScript, поэтому код для его анализа и упаковки вполне естественно вписывается в код JavaScript.
XML
XML — язык разметки, который определяет набор правил для кодирования документов в формате, который читается человеком и читается машиной. Но чем больше информации (вложений, комментариев, вариантов тегов и т.д.) в xml, тем сложнее ее читать человеку.
XML хранит данные в текстовом формате. Это обеспечивает независимый от программного и аппаратного обеспечения способ хранения, транспортировки и обмена данными. XML также облегчает расширение или обновление до новых операционных систем, новых приложений или новых браузеров без потери данных.
Пример синтаксиса:
<?xml version="1.0" encoding="UTF-8"?>
<shiporder orderid="889923"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:noNamespaceSchemaLocation="shiporder.xsd">
<orderperson>John Smith</orderperson>
<shipto>
<name>Ola Nordmann</name>
<address>Langgt 23</address>
<city>4000 Stavanger</city>
<country>Norway</country>
</shipto>
<item>
<title>Empire Burlesque</title>
<note>Special Edition</note>
<quantity>1</quantity>
<price>10.90</price>
</item>
<item>
<title>Hide your heart</title>
<quantity>1</quantity>
<price>9.90</price>
</item>
</shiporder>
Синтаксис XML
- Весь XML документ должен иметь корневой элемент.
- Все теги должны быть закрыты (либо самозакрывающийся тег).
- Все теги должны быть правильно вложены.
- Имена тегов чувствительны к регистру.
- Имена тегов не могут содержать пробелы.
- Значения атрибута должны появляться в кавычках («»).
- Атрибуты не могут иметь вложения (в отличие от тегов).
- Пробел сохраняется.
Преимущества:
- Поддержка метаданных Одним из самых больших преимуществ XML является то, что мы можем помещать метаданные в теги в форме атрибутов. В JSON атрибуты будут добавлены как другие поля-члены в представлении данных, которые НЕ могут быть желательны.
- Визуализация браузера Большинство браузеров отображают XML в удобочитаемой и организованной форме. Древовидная структура XML в браузере позволяет пользователям естественным образом сворачивать отдельные элементы дерева. Эта функция будет особенно полезна при отладке.
- Поддержка смешанного контента Хорошим вариантом использования XML является возможность передачи смешанного контента в пределах одной и той же полезной нагрузки данных. Этот смешанный контент четко различается по разным тегам.
JSON
Что значит JSON
JSON – текстовый формат данных, используемый практически во всех скриптовых языках программирования, однако его истоки находятся у JavaScript. Он имеет сходство с буквенным синтаксисом данного языка программирования, но может использоваться отдельно от него. Многие среды разработки отлично справляются с его чтением и генерированием. JSON находится в состоянии строки, поэтому позволяет передавать информацию по сети. Он преобразуется в объект JS, чтобы пользователь мог прочитать эти данные. Осуществляется это методами языка программирования, но сам JSON методов не имеет, только свойства.
Вы можете сохранить текстовый файл JSON в собственном формате .json, и он будет отображаться как текстовый. Для MIME Type представление меняется на application/json.
Структура JSON
При работе с рассматриваемым текстовым форматом необходимо учитывать правила создания его структуры в объекте, массиве и при присвоении значения. На следующей иллюстрации вы видите наглядную демонстрацию представления объекта.
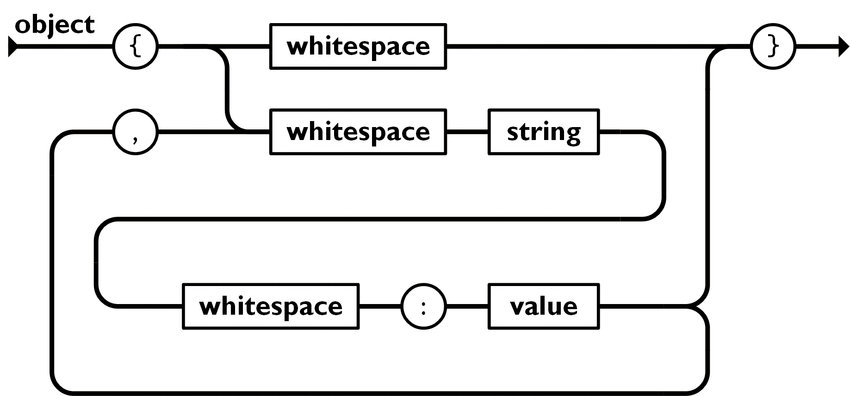
Если речь идет о массиве, здесь тоже необходимо применять определенные правила, поскольку он всегда представляет собой упорядоченную совокупность данных и находится внутри скобок [ ]. При этом значения будут отделены друг от друга.
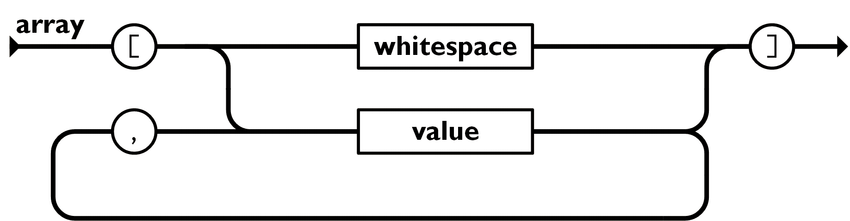
В массиве находятся упомянутые значения, которые могут быть представлены в виде простого текста, чисел, истины, лжи и т.д.
Если вам интересно, на официальном сайте JSON можно найти более детальное описание всех значений и использования формата в разных языках программирования со списком всех доступных библиотек и инструментов.
JavaScript JSON Типы данных
Допустимые типы данных
В JSON значения должны быть одного из следующих типов данных:
- string
- number
- object (JSON объект)
- array
- boolean
- null
Значения JSON не могут быть одним из следующих типов данных:
- function
- date
- undefined
Строки JSON
Строки в JSON должны быть записаны в двойные кавычки.
Пример:
{ "name":"John" }
Числа JSON
Числа в JSON должны быть целыми или с плавающей запятой.
Пример:
{ "age":30 }
Объекты JSON
Значения в JSON могут быть объектами.
Пример:
{ "employee":{ "name":"John", "age":30, "city":"New York" } }
Объекты как значения в JSON должны соответствовать тем же правилам, что и объекты JSON.
Массивы JSON
Значения в JSON могут быть массивами.
Пример:
{ "employees":[ "John", "Anna", "Peter" ] }
Логические значения JSON
Значения в JSON могут быть true/false.
Пример:
{ "sale":true }
JSON null
Значения в JSON могут быть нулевыми.
Пример:
{ "middlename":null }
OpenAPI типы данных*
Ниже приведена ссылка на типы данных не чистого json, а OpenAPI спецификации, которая описывается в формате json, но может содержать совсем другие типы данных. Этот материал со звездочкой и будет полезен для тех, кто собирается изучать проектирование API контрактов.
https://swagger.io/docs/specification/data-models/data-types/
Основные преимущества JSON
Как уже понятно, JSON используется для обмена данными, которые являются структурированными и хранятся в файле или в строке кода. Числа, строки или любые другие объекты отображаются в виде текста, поэтому пользователь обеспечивает простое и надежное хранение информации. JSON обладает рядом преимуществ, которые и сделали его популярным:
- Не занимает много места, является компактным в написании и быстро компилируется.
- Создание текстового содержимого понятно человеку, просто в реализации, а чтение со стороны среды разработки не вызывает никаких проблем. Чтение может осуществляться и человеком, поскольку ничего сложного в представлении данных нет.
- Структура преобразуется для чтения на любых языках программирования.
- Практически все языки имеют соответствующие библиотеки или другие инструменты для чтения данных JSON.
Основной принцип работы JSON
Разберемся, в чем состоит основной принцип работы данного формата, где он используется и чем может быть полезен для обычного пользователя и разработчика.
Ниже приведена примерная структура обработки данных при обращении «клиент-сервер-клиент». Это актуально для передачи информации с сервера в браузер по запросу пользователя, что и является основным предназначением JSON.
- Запрос на сервер отправляется по клику пользователя, например, когда он открывает элемент описания чего-либо для его детального прочтения.
- Запрос генерируется при помощи AJAX с использованием JavaScript и программного сценарного файла PHP. Сам сценарий запущен на сервере, значит, поиск данных завершится успешно.
- Программный файл PHP запоминает всю предоставленную с сервера информацию в виде строки кода.
- JavaScript берет эту строку, восстанавливает ее до необходимого состояния и выводит информацию на странице пользователя в браузере.
На выполнение этой задачи понадобится меньше секунды, и главную роль здесь выполняет встроенный в браузер JavaScript. Если же он по каким-то причинам не функционирует или отсутствует, действие произведено не будет.
Как открыть JSON на компьютере
Если у вас на компьютере обнаружен файл .json, и вы хотите посмотреть его или отредактировать, нужно разобраться, чем его открыть.
Можете использовать практически любой текстовый редактор. Самый простой вариант – встроенный в операционную систему Блокнот. По умолчанию JSON отображается как файл, для которого не выбрана программа для открытия, поэтому при попытке его запуска понадобится выбрать Блокнот.
Известный текстовый редактор с поддержкой синтаксиса разных языков программирования Notepad ++ тоже отлично подойдет для того, чтобы открыть JSON-формат на своем компьютере.
Впрочем, вы можете использовать для этого практически любую среду разработки, поскольку, как уже было сказано выше, JSON поддерживается разными IDE благодаря встроенным или дополнительным библиотекам.
*Лично я пользуюсь VSCode
Создание файла формата JSON
Если же вы хотите создать файл JSON, можно использовать тот же Блокнот.
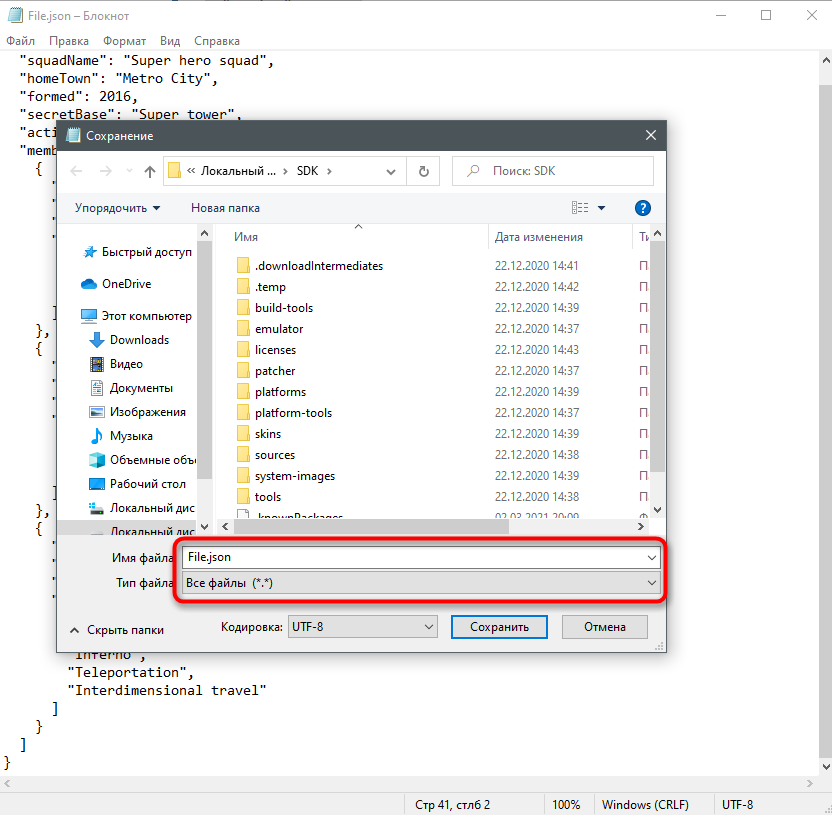
При сохранении вам понадобится выбрать тип файла Все файлы и самостоятельно добавить к названию .json, чтобы текстовый файл сохранился именно в этом формате.
Задание JSON
Написать с нуля (с чистого листа) в текстовом редакторе json, сохранить в нужном формате, загрузить на сайт форматтер, пройти валидацию, раскрыть получившиеся дерево. Сайт-форматтер: Best JSON Formatter and JSON Validator: Online JSON Formatter
Описываем массив пользователей с корзинами и товарами в них. Есть пользователь, его атрибуты, у него массив корзин, у каждой корзины есть свои атрибуты, в каждой корзине массив товаров, которые принадлежат конкретной корзине, ну и конечно у каждого товара присутствуют свои мета данные.
Объекты:
- не менее 1-ого пользователя
- не менее 2-ух корзин у каждого пользователя
- не менее 5-ти товаров в каждой корзине
Атрибуты:
- у пользователя не менее 3-ех атрибутов
- у корзины не менее 5-ти атрибутов
- у товара не менее 5-ти атрибутов
Также необходимо использовать ВСЕ типы данных. Итогом задания будут скриншоты с сайта форматтера с успешной валидацией загруженного вами файла + раскрытым деревом с задуманными вами объектами и их атрибутами.
XML/XSD
XML, в переводе с англ eXtensible Markup Language — расширяемый язык разметки. Используется для хранения и передачи данных. Так что увидеть его можно не только в API, но и в коде.
Этот формат рекомендован Консорциумом Всемирной паутины (W3C), поэтому он часто используется для передачи данных по API. В SOAP API это вообще единственно возможный формат входных и выходных данных.
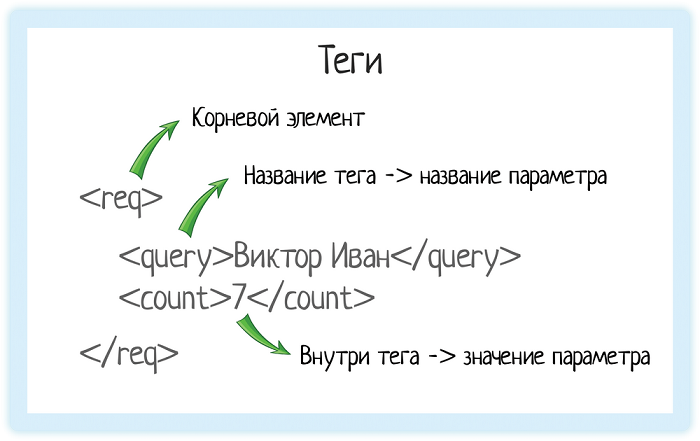
Возьмем пример из документации подсказок Дадаты по ФИО:
<req>
<query>Виктор Иван</query>
<count>7</count>
</req>
И разберемся, что означает эта запись.
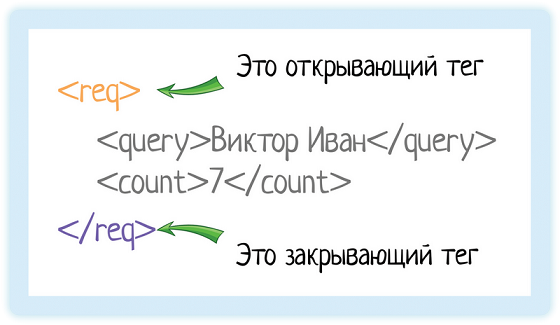
Теги
В XML каждый элемент должен быть заключен в теги. Тег — это некий текст, обернутый в угловые скобки:
<tag>
Текст внутри угловых скобок — название тега. Тега всегда два:
- Открывающий — текст внутри угловых скобок
<tag>
- Закрывающий — тот же текст (это важно!), но добавляется символ «/»
</tag>
Ой, ну ладно, подловили! Не всегда. Бывают еще пустые элементы, у них один тег и открывающий, и закрывающий одновременно. Но об этом чуть позже!
С помощью тегов мы показываем системе «вот тут начинается элемент, а вот тут заканчивается». Это как дорожные знаки:
— На въезде в город написано его название: Москва — На выезде написано то же самое название, но перечеркнутое: Москва*
- Пример с дорожными знаками я когда-то давно прочитала в статье Яндекса, только ссылку уже не помню. А пример отличный!

Корневой элемент
В любом XML-документе есть корневой элемент. Это тег, с которого документ начинается, и которым заканчивается. В случае REST API документ — это запрос, который отправляет система. Или ответ, который она получает.
Чтобы обозначить этот запрос, нам нужен корневой элемент. В подсказках корневой элемент — «req».

Он мог бы называться по другому:
<main>
<sugg>
Да как угодно. Он показывает начало и конец нашего запроса, не более того. А вот внутри уже идет тело документа — сам запрос. Те параметры, которые мы передаем внешней системе. Разумеется, они тоже будут в тегах, но уже в обычных, а не корневых.
Значение элемента
Значение элемента хранится между открывающим и закрывающим тегами. Это может быть число, строка, или даже вложенные теги!
Вот у нас есть тег «query». Он обозначает запрос, который мы отправляем в подсказки.

Внутри — значение запроса.
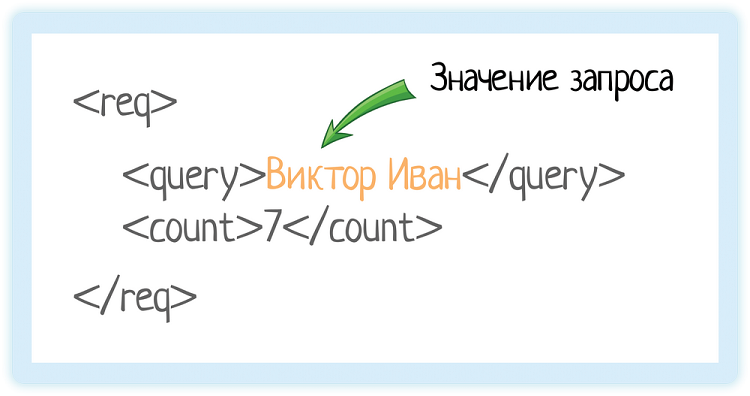
Это как если бы мы вбили строку «Виктор Иван» в GUI (графическом интерфейсе пользователя):
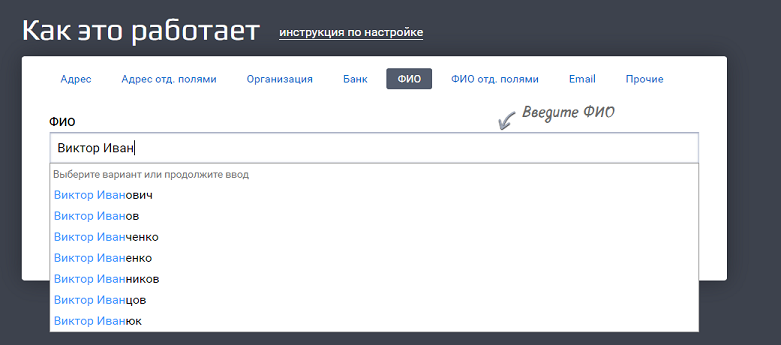
Пользователю лишняя обвязка не нужна, ему нужна красивая формочка. А вот системе надо как-то передать, что «пользователь ввел именно это». Как показать ей, где начинается и заканчивается переданное значение? Для этого и используются теги.
Система видит тег «query» и понимает, что внутри него «строка, по которой нужно вернуть подсказки».
Параметр count = 7 обозначает, сколько подсказок вернуть в ответе. Если тыкать подсказки на демо-форме Дадаты, нам вернется 7 подсказок. Это потому, что туда вшито как раз значение count = 7. А вот если обратиться к документации метода, count можно выбрать от 1 до 20.
Откройте консоль разработчика через f12, вкладку Network, и посмотрите, какой запрос отправляется на сервер. Там будет значение count = 7.См также:Что тестировщику надо знать про панель разработчика — подробнее о том, как использовать консоль.

Обратите внимание:
- Виктор Иван — строка
- 7 — число
Но оба значения идут без кавычек. В XML нам нет нужды брать строковое значение в кавычки (а вот в JSON это сделать придется).
Атрибуты элемента
У элемента могут быть атрибуты — один или несколько. Их мы указываем внутри отрывающегося тега после названия тега через пробел в виде
название\_атрибута = «значение атрибута»
Например:
<query attr1="value 1">Виктор Иван</query>
<query attr1="value 1" attr2="value 2">Виктор Иван</query>

Зачем это нужно? Из атрибутов принимающая API-запрос система понимает, что такое ей вообще пришло.
Например, мы делаем поиск по системе, ищем клиентов с именем Олег. Отправляем простой запрос:
<query>Олег</query>
А в ответ получаем целую пачку Олегов! С разными датами рождения, номерами телефонов и другими данными. Допустим, что один из результатов поиска выглядит так:
<party type="PHYSICAL" sourceSystem="AL" rawId="2">
<field name="name">Олег </field>
<field name="birthdate">02.01.1980</field>
<attribute type="PHONE" rawId="AL.2.PH.1">
<field name="type">MOBILE</field>
<field name="number">+7 916 1234567</field>
</attribute>
</party>
Давайте разберем эту запись. У нас есть основной элемент party.
У него есть 3 атрибута:
- type = «PHYSICAL» — тип возвращаемых данных. Нужен, если система умеет работать с разными типами: ФЛ, ЮЛ, ИП. Тогда благодаря этому атрибуту мы понимаем, с чем именно имеем дело и какие поля у нас будут внутри. А они будут отличаться! У физика это может быть ФИО, дата рождения ИНН, а у юр лица — название компании, ОГРН и КПП
- sourceSystem = «AL» — исходная система. Возможно, нас интересуют только физ лица из одной системы, будем делать отсев по этому атрибуту.
- rawId = «2» — идентификатор в исходной системе. Он нужен, если мы шлем запрос на обновление клиента, а не на поиск. Как понять, кого обновлять? По связке sourceSystem + rawId!
Внутри party есть элементы field.

У элементов field есть атрибут name. Значение атрибута — название поля: имя, дата рождения, тип или номер телефона. Так мы понимаем, что скрывается под конкретным field.
Это удобно с точки зрения поддержки, когда у вас коробочный продукт и 10+ заказчиков. У каждого заказчика будет свой набор полей: у кого-то в системе есть ИНН, у кого-то нету, одному важна дата рождения, другому нет, и т.д.
Но, несмотря на разницу моделей, у всех заказчиков будет одна XSD-схема (которая описывает запрос и ответ):
— есть элемент party; — у него есть элементы field; — у каждого элемента field есть атрибут name, в котором хранится название поля.
А вот конкретные названия полей уже можно не описывать в XSD. Их уже «смотрите в ТЗ». Конечно, когда заказчик один или вы делаете ПО для себя или «вообще для всех», удобнее использовать именованные поля — то есть «говорящие» теги. Какие плюшки у этого подхода:
— При чтении XSD сразу видны реальные поля. ТЗ может устареть, а код будет актуален. — Запрос легко дернуть вручную в SOAP Ui — он сразу создаст все нужные поля, нужно только значениями заполнить. Это удобно тестировщику + заказчик иногда так тестирует, ему тоже хорошо.
В общем, любой подход имеет право на существование. Надо смотреть по проекту, что будет удобнее именно вам. У меня в примере неговорящие названия элементов — все как один будут field. А вот по атрибутам уже можно понять, что это такое.
Помимо элементов field в party есть элемент attribute. Не путайте xml-нотацию и бизнес-прочтение:
- с точки зрения бизнеса это атрибут физ лица, отсюда и название элемента — attribute.
- с точки зрения xml — это элемент (не атрибут!), просто его назвали attribute. XML все равно (почти), как вы будете называть элементы, так что это допустимо.

У элемента attribute есть атрибуты:
- type = «PHONE» — тип атрибута. Они ведь разные могут быть: телефон, адрес, емейл...
- rawId = «AL.2.PH.1» — идентификатор в исходной системе. Он нужен для обновления. Ведь у одного клиента может быть несколько телефонов, как без ID понять, какой именно обновляется?

Такая вот XML-ка получилась. Причем упрощенная. В реальных системах, где хранятся физ лица, данных сильно больше: штук 20 полей самого физ лица, несколько адресов, телефонов, емейл-адресов…
Но прочитать даже огромную XML не составит труда, если вы знаете, что где. И если она отформатирована — вложенные элементы сдвинуты вправо, остальные на одном уровне. Без форматирования будет тяжеловато…
А так всё просто — у нас есть элементы, заключенные в теги. Внутри тегов — название элемента. Если после названия идет что-то через пробел: это атрибуты элемента.
XML пролог
Иногда вверху XML документа можно увидеть что-то похожее:
<?xml version="1.0" encoding="UTF-8"?>
Эта строка называется XML прологом. Она показывает версию XML, который используется в документе, а также кодировку. Пролог необязателен, если его нет — это ок. Но если он есть, то это должна быть первая строка XML документа.
UTF-8 — кодировка XML документов по умолчанию.
Задание XML
Написать с нуля (с чистого листа) в текстовом редакторе xml, сохранить в нужном формате, загрузить на сайт форматтер, пройти валидацию, раскрыть получившиеся дерево. Сайт-форматтер: https://jsonformatter.org/xml-formatter
Описываем массив пользователей с корзинами и товарами в них. Есть пользователь, его атрибуты, у него массив корзин, у каждой корзины есть свои атрибуты, в каждой корзине массив товаров, которые принадлежат конкретной корзине, ну и конечно у каждого товара присутствуют свои мета данные.
Объекты:
- не менее 1-ого пользователя
- не менее 2-ух корзин у каждого пользователя
- не менее 5-ти товаров в каждой корзине
Атрибуты:
- у пользователя не менее 3-ех атрибутов
- у корзины не менее 5-ти атрибутов
- у товара не менее 5-ти атрибутов
Итогом задания будут скриншоты с сайта форматтера с успешной валидацией загруженного вами файла + раскрытым деревом с задуманными вами объектами и их атрибутами.
XSD-схема
XSD (XML Schema Definition) — это описание вашего XML. Как он должен выглядеть, что в нем должно быть? Это ТЗ, написанное на языке машины — ведь схему мы пишем… Тоже в формате XML! Получается XML, который описывает другой XML.
Фишка в том, что проверку по схеме можно делегировать машине. И разработчику даже не надо расписывать каждую проверку. Достаточно сказать «вот схема, проверяй по ней».
Если мы создаем SOAP-метод, то указываем в схеме:
- какие поля будут в запросе;
- какие поля будут в ответе;
- какие типы данных у каждого поля;
- какие поля обязательны для заполнения, а какие нет;
- есть ли у поля значение по умолчанию, и какое оно;
- есть ли у поля ограничение по длине;
- есть ли у поля другие параметры;
- какая у запроса структура по вложенности элементов;
- ...
Теперь, когда к нам приходит какой-то запрос, он сперва проверяется на корректность по схеме. Если запрос правильный, запускаем метод, отрабатываем бизнес-логику. А она может быть сложной и ресурсоемкой! Например, сделать выборку из многомиллионной базы. Или провести с десяток проверок по разным таблицам базы данных…
Поэтому зачем запускать сложную процедуру, если запрос заведом «плохой»? И выдавать ошибку через 5 минут, а не сразу? Валидация по схеме помогает быстро отсеять явно невалидные запросы, не нагружая систему.
Более того, похожую защиту ставят и некоторые программы-клиенты для отправки запросов. Например, SOAP Ui умеет проверять ваш запрос на well formed xml, и он просто не отправит его на сервер, если вы облажались. Экономит время на передачу данных, молодец!
А простому пользователю вашего SOAP API схема помогает понять, как составить запрос. Кто такой «простой пользователь»?
- Разработчик системы, использующей ваше API — ему надо прописать в коде, что именно отправлять из его системы в вашу.
- Тестировщик, которому надо это самое API проверить — ему надо понимать, как формируется запрос.
Да-да, в идеале у нас есть подробное ТЗ, где всё хорошо описано. Но увы и ах, такое есть не всегда. Иногда ТЗ просто нет, а иногда оно устарело. А вот схема не устареет, потому что обновляется при обновлении кода. И она как раз помогает понять, как запрос должен выглядеть.
Итого, как используется схема при разработке SOAP API:
- Наш разработчик пишет XSD-схему для API запроса: нужно передать элемент такой-то, у которого будут такие-то дочерние, с такими-то типами данных. Эти обязательные, те нет.
- Разработчик системы-заказчика, которая интегрируется с нашей, читает эту схему и строит свои запросы по ней.
- Система-заказчик отправляет запросы нам.
- Наша система проверяет запросы по XSD — если что-то не так, сразу отлуп.
- Если по XSD запрос проверку прошел — включаем бизнес-логику!
А теперь давайте посмотрим, как схема может выглядеть! Возьмем для примера метод doRegister в Users. Чтобы отправить запрос, мы должны передать email, name и password. Есть куча способов написать запрос правильно и неправильно:
| Правильный запрос | Неправильный запрос |
|---|---|
| ... | ... |
<wrap:doRegister> <email>olga@gmail.com</email> <name>Ольга</name> <password>1</password> </wrap:doRegister> | <wrap:doRegister> <email>name@gmail.com</email> <password>1</password> </wrap:doRegister>Нет обязательного поля name |
<wrap:doRegister> <email>maxim@gmail.com</email> <name>*(&$%*($</name> <password>Парольчик</password> </wrap:doRegister> | <wrap:doRegister> <mail>test@gmail.com</mail> <name>Test</name> <password>1</password> </wrap:doRegister>Опечатка в названии тега (mail вместо email) |
Попробуем написать для него схему. В запросе должны быть 3 элемента (email, name, password) с типом «string» (строка). Пишем:
<xs:element name="doRegister ">
<xs:complexType>
<xs:sequence>
<xs:element name="email" type="xs:string"/>
<xs:element name="name" type="xs:string"/>
<xs:element name="password" type="xs:string"/>
</xs:sequence>
</xs:complexType>
</xs:element>
А в WSDl сервиса она записана еще проще:
<message name="doRegisterRequest">
<part name="email" type="xsd:string"/>
<part name="name" type="xsd:string"/>
<part name="password" type="xsd:string"/>
</message>
Конечно, в схеме могут быть не только строковые элементы. Это могут быть числа, даты, boolean-значения и даже какие-то свои типы:
<xsd:complexType name="Test">
<xsd:sequence>
<xsd:element name="value" type="xsd:string"/>
<xsd:element name="include" type="xsd:boolean" minOccurs="0" default="true"/>
<xsd:element name="count" type="xsd:int" minOccurs="0" length="20"/>
<xsd:element name="user" type="USER" minOccurs="0"/>
</xsd:sequence>
</xsd:complexType>
А еще в схеме можно ссылаться на другую схему, что упрощает написание кода — можно переиспользовать схемы для разных задач.
Язык определения схем XSD
Консорциум W3C выработал рекомендацию языка определения схем XML (XSD), объединив наиболее популярные языки описания схем в один стандарт. Основная цель, которая при этом преследовалась, — получение стандарта, который можно широко реализовать и при этом он платформно-независимый.
Язык XML Schema Definition Language, который также называют XML Schema Language, во многом похож на язык XDR. Схемы XSD способны решать следующие задачи:
- Перечисление элементов в документе XML и проверка наличия в документе только объявленных элементов.
- Объявление и определение атрибутов, модифицирующих элементы документа.
- Определение родительско-дочерних отношений между элементами.
- Определение состояний и моделей содержания для элементов и атрибутов.
- Задание типов данных.
- Установка значений по умолчанию.
- Возможность расширения.
- Поддержка использования пространств имен.
Корневым элементом в схеме XML является элемент Schema, который содержит все остальные элементы в документе схемы. В рамках корневого элемента схемы XSD атрибутом xmlns определяется пространство имен XMLSchema, которое содержит элементы и атрибуты XSD схемы.
<xsd:schema xmlns:xsd="http://www.w3.org/2001/XMLSchema">
Все элементы XSD начинаются с префикса xsd:, который указывается для пространства имен XSD, объявленного в корневом элементе экземпляра схемы.
XML-документ, который проверяется с помощью схемы, также должен содержать объявление пространства имен. Пространство имен всегда указывается в корневом элементе экземпляра документа с помощью атрибута xmlns:
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
Это пространство имен содержит элементы и атрибуты XMLSchema, которые можно включать в документ XML. По общему соглашению префикс xsi используется для этого пространства имен и добавляется в начале имен всех элементов и атрибутов, принадлежащих пространству имен, отделяясь от них двоеточием.
Ссылка на конкретную схему приводится в атрибуте
xsi:schemaLocation="http://kit.znu.edu.ua/scemes/имя\_файла.xsd"Объявление элемента и атрибута XSD
Процесс создания схемы включает в себя два шага — определение и объявление типов элементов или типов атрибутов. Элементы и атрибуты XML-документа объявляются элементами схемы xsd:element и xsd:attribute. Структура же XML-документа определяется элементами схемы xsd:simpleType и xsd:complexType.
Основное объявление элемента состоит из имени и типа данных
<xsd:element name="имя_элемента" type="xsd:тип_данных"/>
В схемах XSD дескрипторы, используемые в документах XML, разделяются на две категории — сложные типы и простые типы. Элементы сложных типов могут содержать другие элементы, а также обладают определенными атрибутами; элементы простых типов такими возможностями не обладают.
Атрибут - объявление простого типа, которое не может содержать другие элементы. Объявление атрибута похоже на объявление элемента:
<xsd:attribute name="имя_атрибута" type="xsd:тип_данных"/>
Простые типы данных
Есть две главных категории простых типов:
- встроенные типы;
- определенные пользователем простые типы.
Язык XSD имеет большое количество встроенных простых типов данных. Встроенные типы включают в себя примитивные типы и производные. Примитивные типы данных не получены из других типов данных. Например, числа с плавающей запятой - математическое понятие, которое не получено из других типов данных. Производные типы данных определены в терминах существующих типов данных. Например, целое число - частный случай, полученный из десятичного типа данных.
Следующая таблица представляет список примитивных типов данных XML-схемы, аспекты, которые могут быть применены к типу данных и описания типа данных.
| Тип данных | Аспекты | Описание |
|---|---|---|
| string | length, pattern, maxLength, minLength, enumeration, whiteSpace | Представляет символьную строку. |
| Boolean | pattern, whiteSpace | Представляет логическое значение, которое может быть true или false. |
| decimal | enumeration, pattern, totalDigits, fractionDigits, minInclusive, minExclusive, maxInclusive, maxExclusive, whiteSpace | Представляет произвольное число. |
| float | pattern, enumeration, minInclusive, minExclusive, maxInclusive, maxExclusive, whiteSpace | Представляет 32-битовое число с плавающей запятой одиночной точности. |
| double | pattern, enumeration, minInclusive, minExclusive, maxInclusive, maxExclusive, whiteSpace | Представляет 64-битовое число с плавающей запятой двойной точности. |
| duration | enumeration, pattern, minInclusive, minExclusive, maxInclusive, maxExclusive, whiteSpace | Представляет продолжительность времени. Шаблон для duration следующий - PnYnMnDTnHnMnS, где nY представляет число лет; nM - месяцев; nD - дней; Т - разделитель даты и времени; nH - число часов; nM - минут; nS - секунд. |
| dateTime | enumeration, pattern, minInclusive, minExclusive, maxInclusive, maxExclusive, whiteSpace | Представляет конкретное время. Шаблон для dateTime следующий - CCYY-MM-DDThh:mm:ss, где CC представляет столетие; YY - год; MM - месяц; DD - день; Т - разделитель даты и времени; hh - число часов; mm - минут; ss - секунд. При необходимости можно указывать доли секунды. Например, сотые доли в шаблоне: ss.ss |
| time | enumeration, pattern, minInclusive, minExclusive, maxInclusive, maxExclusive, whiteSpace | Представляет конкретное время дня. Шаблон для time следующий -hh:mm:ss.sss (долевая часть секунд необязательна). |
| date | enumeration, pattern, minInclusive, minExclusive, maxInclusive, maxExclusive, whiteSpace | Представляет календарную дату. Шаблон для date такой - CCYY-MM-DD (здесь необязательна часть, представляющая время). |
| gYearMonth | enumeration, pattern, minInclusive, minExclusive, maxInclusive, maxExclusive, whiteSpace | Представляет конкретный месяц конкретного года (CCYY-MM ). |
| gYear | enumeration, pattern, minInclusive, minExclusive, maxInclusive, maxExclusive, whiteSpace | Представляет календарный год (CCYY). |
| gMonthDay | enumeration, pattern, minInclusive, minExclusive, maxInclusive, maxExclusive, whiteSpace | Представляет конкретный день конкретного месяца (--MM-DD). |
| gDay | enumeration, pattern, minInclusive, minExclusive, maxInclusive, maxExclusive, whiteSpace | Представляет календарный день (---DD). |
| gMonth | enumeration, pattern, minInclusive, minExclusive, maxInclusive, maxExclusive, whiteSpace | Представляет календарный месяц (--MM--). |
| hexBinary | length, pattern, maxLength, minLength, enumeration, whiteSpace | Представляет произвольную шестнадцатерично-закодированную двоичную информацию. HexBinary - набор двоичных октетов фиксированной длины, состоящий из четырех пар шестнадцатеоисных символов. Например, 0-9a-fA-F. |
| base64Binary | length, pattern, maxLength, minLength, enumeration, whiteSpace | Представляет произвольную Base64-закодированную двоичную информацию. Base64Binary - набор двоичных октетов фиксированной длины. |
| anyURI | length, pattern, maxLength, minLength, enumeration, whiteSpace | Представляет URI как определено в RFC 2396. Значение anyURI может быть абсолютно или относительно, и может иметь необязательный идентификатор фрагмента. |
| QName | length, enumeration, pattern, maxLength, minLength, whiteSpace | Представляет составное имя. Имя составлено из префикса и локального названия, отделенного двоеточием. И префикс и локальные названия должны быть NCNAME. Префикс должен быть связан с namespace URI ссылкой, используя объявление пространства имени. |
| NOTATION | length, enumeration, pattern, maxLength, minLength, whiteSpace | Представляет тип атрибута СИСТЕМЫ ОБОЗНАЧЕНИЙ. Набор QNAMES. |
Следующая таблица представляет список производных типов данных XML-схемы, аспекты, которые могут быть применены к типу данных и описания типа данных.
| Тип данных | Аспекты | Описание |
|---|---|---|
| normalizedString | length, pattern, maxLength, minLength, enumeration, whiteSpace | Представляет нормализованные строки. Этот тип данных получен из string. |
| token | enumeration, pattern, length, minLength, maxLength, whiteSpace | Представляет маркированные строки. Этот тип данных получен из normalizedString. |
| language | length, pattern, maxLength, minLength, enumeration, whiteSpace | Представляет идентификаторы естественного языка (определенный RFC 1766). Этот тип данных получен из token |
| IDREFS | length, maxLength, minLength, enumeration, whiteSpace | Представляет тип атрибута IDREFS. Содержит набор значений типа IDREF. |
| ENTITIES | length, maxLength, minLength, enumeration, whiteSpace | Представляет тип атрибута ENTITIES. Содержит набор значений типа ENTITY. |
| NMTOKEN | length, pattern, maxLength, minLength, enumeration, whiteSpace | Представляет тип атрибута NMTOKEN. NMTOKEN - набор символов имен (символы, цифры и другие символы) в любой комбинации. В отличие отName и NCNAME, NMTOKEN не имеет никаких ограничений на первый символ. Этот тип данных получен из token. |
| NMTOKENS | length, maxLength, minLength, enumeration, whiteSpace | Представляет тип атрибута NMTOKENS. Содержит набор значений типа NMTOKEN. |
| Name | length, pattern, maxLength, minLength, enumeration, whiteSpace | Представляет имена в XML. Name - лексема(маркер), которая начинается с символа, символа подчеркивания или двоеточия и продолжается символами имен (символы, цифры, и другие символы). Этот тип данных получен из token. |
| NCName | length, pattern, maxLength, minLength, enumeration, whiteSpace | Представляет неколонкированные названия. Этот тип данных - тот же, что и Name, но не может начинаться с двоеточия. Этот тип данных получен из Name. |
| ID | length, enumeration, pattern, maxLength, minLength, whiteSpace | Представляет тип атрибута ID, определенный в XML 1.0 Рекомендации. ИДЕНТИФИКАТОР не должен иметь двоеточия (NCName) и должен быть уникален в пределах XML документа. Этот тип данных получен из NCNAME. |
| IDREF | length, enumeration, pattern, maxLength, minLength, whiteSpace | Представляет ссылку к элементу, имеющему атрибут ID, который точно соответствует установленному ИДЕНТИФИКАТОРУ. IDREF должен быть NCNAME и должен быть значением элемента или атрибута типа ID в пределах XML документа. Этот тип данных получен из NCNAME. |
| ENTITY | length, enumeration, pattern, maxLength, minLength, whiteSpace | Представляет тип атрибута ENTITY. Это - ссылка к неанализируемому объекту с именем, которое точно соответствует установленному имени. ENTITY должен быть NCNAME и должен быть объявлен в схеме как неанализируемое имя объекта. Этот тип данных получен из NCNAME. |
| integer | enumeration, fractionDigits, pattern, minInclusive, minExclusive, maxInclusive, maxExclusive, totalDigits, whiteSpace | Представляет последовательность десятичных цифр с необязательным знаком (+ или -). Этот тип данных получен из decimal. |
| nonPositiveInteger | enumeration, fractionDigits, pattern, minInclusive, minExclusive, maxInclusive, maxExclusive, totalDigits, whiteSpace | Представляет целое число, меньшее или равное нулю. NonPositiveInteger состоит из отрицательного знака (-) и последовательности десятичных цифр. Этот тип данных получен из целого числа. |
| negativeInteger | enumeration, fractionDigits, pattern, minInclusive, minExclusive, maxInclusive, maxExclusive, totalDigits, whiteSpace | Представляет целое число, меньшее нуля. Этот тип данных получен из nonPositiveInteger. |
| long | enumeration, fractionDigits, pattern, minInclusive, minExclusive, maxInclusive, maxExclusive, totalDigits, whiteSpace | Представляет целое число с минимальным значением -9223372036854775808 и максимумом 9223372036854775807. Этот тип данных получен из целого числа. |
| int | enumeration, fractionDigits, pattern, minInclusive, minExclusive, maxInclusive, maxExclusive, totalDigits, whiteSpace | Представляет целое число с минимальным значением -2147483648 и максимумом 2147483647. Этот тип данных получен из long. |
| short | enumeration, fractionDigits, pattern, minInclusive, minExclusive, maxInclusive, maxExclusive, totalDigits, whiteSpace | Представляет целое число с минимальным значением -32768 и максимумом 32767. Этот тип данных получен из int. |
| byte | enumeration, fractionDigits, pattern, minInclusive, minExclusive, maxInclusive, maxExclusive, totalDigits, whiteSpace | Представляет целое число с минимальным значением -128 и максимумом 127. Этот тип данных получен из short. |
| nonNegativeInteger | enumeration, fractionDigits, pattern, minInclusive, minExclusive, maxInclusive, maxExclusive, totalDigits, whiteSpace | Представляет целое число, большее равное нулю. Этот тип данных получен из целого числа. |
| unsignedLong | enumeration, fractionDigits, pattern, minInclusive, minExclusive, maxInclusive, maxExclusive, totalDigits, whiteSpace | Представляет целое число с минимумом нуль и максимумом 18446744073709551615. Этот тип данных получен из nonNegativeInteger. |
| unsignedInt | enumeration, fractionDigits, pattern, minInclusive, minExclusive, maxInclusive, maxExclusive, totalDigits, whiteSpace | Представляет целое число с минимумом нуль и максимумом 4294967295. Этот тип данных получен из unsignedLong. |
| unsignedShort | enumeration, fractionDigits, pattern, minInclusive, minExclusive, maxInclusive, maxExclusive, totalDigits, whiteSpace | Представляет целое число с минимумом нуль и максимумом 65535. Этот тип данных получен из unsignedInt. |
| unsignedByte | enumeration, fractionDigits, pattern, minInclusive, minExclusive, maxInclusive, maxExclusive, totalDigits, whiteSpace | Представляет целое число с минимумом нуля и максимума 255. Этот тип данных получен из unsignedShort. |
| positiveInteger | enumeration, fractionDigits, pattern, minInclusive, minExclusive, maxInclusive, maxExclusive, totalDigits, whiteSpace | Представляет целое число, которое является большим чем нуль. Этот тип данных получен из nonNegativeInteger. |
Определённые пользователем простые типы
Получены из встроенных типов, применением к ним именованых ограничений, называемыми аспектами(Facets). Аспекты ограничивают допустимые значения простых типов. Синтаксис применения аспектов ограничения следующий:
<xsd:restriction base="тип\_данных"> <xsd:имя\_аспекта value="значение\_аспекта"/> </xsd:restriction>
| Аспект | Значение |
|---|---|
| enumeration | Определенный набор значений. Ограничивает тип данных указанными значениями. |
| fractionDigits | Значение с определенным максимальным числом десятичных цифр в дробной части. |
| length | Целочисленное число единиц длины. Единицы длины зависят от типа данных. |
| maxExclusive | Верхний предел значений (все значения - меньше указанного). |
| maxInclusive | Максимальное значение. |
| maxLength | Целочисленное число единиц максимальной длины. |
| minExclusive | Нижний предел значений (все значения - больше указанного). |
| minInclusive | Минимальное значение. |
| minLength | Целочисленное число единиц минимальной длины. |
| pattern | Литеральный шаблон, которому должны соответствовать значения. |
| totalDigits | Значение с определенным максимальным числом десятичных цифр. |
| whiteSpace | Одно из предопределенных значений: preserve, replace или collapse |
| Значение | Описание |
|---|---|
| preserve | Никакая нормализация не выполняется. |
| replace | Все #x9 (tab), #xA (line feed) and #xD (carriage return) заменяются на #x20 (пробел). |
| collapse | После replace-обработки все внутренние цепочки #x20 разрушаются до одного пробела, а окружающие пробелы удаляются. |
Аспекты могут быть указаны только однажды в определении типа, кроме enumeration и pattern - они могут иметь многократные вхождения и группируются.
Именованный тип данных
В языке XSD, в отличие от тех двух, с которыми вы познакомились раньше, существует концепция именованных типов. Например, при создании определения, можно присвоить этому определению имя, чтобы повторно использовать его в схеме XSD. Вы можете создать определение простого типа simpleType и назвать его, например, txt15pre. В результате вы получите именованное ограничение. После этого вы сможете применять это ограничение и к другим элементам в схеме. Это особенно полезно, когда в определении применяются аспекты ограничения типа данных, чтобы не повторять их каждый раз в других определениях. Например, элемент simpleType может быть связан с элементом Фамилия и атрибутом Телефон для объявления содержания этих элемента и значения атрибута как строковых данных:
<xsd:simpleType name="txt15pre">
<xsd:restriction base="xsd:string">
<xsd:maxLength value="15"/>
<xsd:whiteSpace value="preserve"/>
</xsd:restriction>
</xsd:simpleType>
<xsd:element name="Фамилия" type="txt15pre"/>
<xsd:attribute name="Телефон" type="txt15pre" use="required"/>
Обратили внимание на ключевое слово required в объявлении атрибута? Как и в предыдущих схемах, оно все так же означает обязательность использования объявленного атрибута. Другими предопределенными значениями атрибута use элемента схемы xsd:attribute могут быть ключевые слова optional и prohibited. Если первое из них означает необязательность использования, то второе запрещает использование объявленного атрибута. Такая необходимость возникает в случае локального объявления ранее определенной группы атрибутов элементом схемы xsd:attributeGroup, например:
<xsd:attributeGroup name="Связь">
<xsd:attribute name="Телефон" type="txt15pre"/>
<xsd:attribute name="Факс" type="txt15pre"/>
</xsd:attributeGroup>
далее в контексте определения элемента сложного типа мы делаем ограничение на применение атрибутов этой группы:
<xsd:complexType name="Клиент">
<xsd:complexContent>
<xsd:restriction base="xsd:Связь">
<xsd:attribute name="Телефон" use="required"/>
<xsd:attribute name="Факс" use="prohibited"/>
</xsd:restriction>
</xsd:complexContent>
</xsd:complexType>
Сложные типы данных
Модель содержания элемента сложного типа - формальное описание структуры и допустимого содержания элемента, которое используется для проверки правильности XML документа. Модели содержания Схемы предоставляют больший контроль структуры элементов, чем модели содержания DTD. Кроме того, модели содержания схемы позволяют проверять правильность смешанного содержания.
Модель содержания может ограничивать документ до некоторого набора элементных типов и атрибутов, описывать и поддерживать связи между этими различными компонентами и уникально обозначать отдельные элементы. Свободное использование модели содержания позволяет разработчикам изменять структурную информацию.
Перечень объявлений дочерних элементов приводится в структуре группирующих XSD-элементов choice, sequence, и all.
Элемент xsd:choice позволяет только одному из элементов, содержащихся в группе присутствовать в составе элемента. Элемент xsd:sequence требует появления элементов группы в точно установленной последовательности в составе элемента. xsd:all элемент позволяет элементам в группе быть (или не быть) в любом порядке в составе элемента.
Элемент xsd:group используется для четкого определения группы и для ссылки к именованной группе. Вы можете использовать модель группы, чтобы определить набор элементов, которые могут быть повторены в документе. Это полезно для формирования определения комплексного типа. Именованную модель группы можно далее определить, используя <xsd:sequence>, <xsd:choice> или <xsd:all> дочерние элементы. Именованные группы должны определяться в корне схемы. При необходимости многократного использования перечня элементов, определенного в группе, не надо каждый раз писать этот перечень - достаточно дать ссылку на именованную группу <xsd:group ref="имя_группы">
Определение элемента сложного типа
Определения сложных типов создаются с использованием элемента complexType, его атрибутов и любых допустимых аспектов. Обычно, сложные типы будут содержать набор элементных объявлений, объявлений атрибутов и элементных ссылок.
<xsd:element name="имя_элемента" type="xsd:тип_данных">
<xsd:complexType>
<xsd:sequence>
<xsd:element name="имя_элемента" type="xsd:тип_данных"/>
</xsd:sequence>
<xsd:attribute name="имя_атрибута" type="xsd:тип_данных"/>
</xsd:complexType>
</xsd:element>
Листинг 1. Пример XSD-схемы "Картотека.xsd"
<xsd:schema xmlns:xsd="http://www.w3.org/2001/XMLSchema">
<xsd:element name="Заказчики">
<xsd:complexType>
<xsd:sequence maxOccurs="unbounded">
<xsd:element name="Заказчик">
<xsd:complexType>
<xsd:sequence>
<xsd:element name="Компания">
<xsd:complexType>
<xsd:attribute name="телефон"
type="xsd:string" use="required"/>
</xsd:complexType>
</xsd:element>
</xsd:sequence>
</xsd:complexType>
</xsd:element>
</xsd:sequence>
</xsd:complexType>
</xsd:element>
</xsd:schema>
Практика: составляем свой запрос
Ок, теперь мы знаем, как «прочитать» запрос для API-метода в формате XML. Но как его составить по ТЗ? Давайте попробуем. Смотрим в документацию. И вот почему я даю пример из Дадаты — там классная документация!
Что, если я хочу, чтобы мне вернуть только женские ФИО, начинающиеся на «Ан»? Берем наш исходный пример:
<req>
<query>Виктор Иван</query>
<count>7</count>
</req>
В первую очередь меняем сам запрос. Теперь это уже не «Виктор Иван», а «Ан»:
<req>
<query>Ан</query>
<count>7</count>
</req>
Далее смотрим в ТЗ. Как вернуть только женские подсказки? Есть специальный параметр — gender. Название параметра — это название тегов. А внутри уже ставим пол. «Женский» по английски будет FEMALE, в документации также. Итого получили:
<req>
<query>Ан</query>
<count>7</count>
<gender>FEMALE</gender>
</req>
Ненужное можно удалить. Если нас не волнует количество подсказок, параметр count выкидываем. Ведь, согласно документации, он необязательный. Получили запрос:
<req>
<query>Ан</query>
<gender>FEMALE</gender>
</req>
Вот и все! Взяли за основу пример, поменяли одно значение, один параметр добавили, один удалили. Не так уж и сложно. Особенно, когда есть подробное ТЗ и пример)))
Задание XSD*
Задание со звездочкой, не обязательное, по желанию!
Напишите запрос для метода MagicSearch в Users. Мы хотим найти всех Ивановых по полному совпадению, на которых висят актуальные задачи.
Well Formed XML
Разработчик сам решает, какой XML будет считаться правильным, а какой нет. Но есть общие правила, которые нельзя нарушать. XML должен быть well formed, то есть синтаксически корректный.
Чтобы проверить XML на синтаксис, можно использовать любой XML Validator (так и гуглите). Я рекомендую сайт w3schools. Там есть сам валидатор + описание типичных ошибок с примерами.
В готовый валидатор вы просто вставляете свой XML (например, запрос для сервера) и смотрите, всё ли с ним хорошо. Но можете проверить его и сами. Пройдитесь по правилам синтаксиса и посмотрите, следует ли им ваш запрос.
Правила well formed XML:
- Есть корневой элемент.
- У каждого элемента есть закрывающийся тег.
- Теги регистрозависимы!
- Соблюдается правильная вложенность элементов.
- Атрибуты оформлены в кавычках.
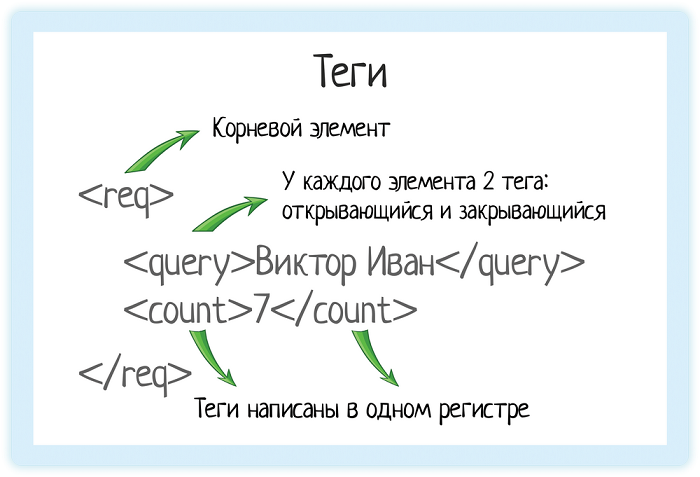
Давайте пройдемся по каждому правилу и обсудим, как нам применять их в тестировании. То есть как правильно «ломать» запрос, проверяя его на well-formed xml. Зачем это нужно? Посмотреть на фидбек от системы. Сможете ли вы по тексту ошибки понять, где именно облажались?
См также: Сообщения об ошибках — тоже документация, тестируйте их! — зачем тестировать сообщения об ошибках
1. Есть корневой элемент
Нельзя просто положить рядышком 2 XML и полагать, что «система сама разберется, что это два запроса, а не один». Не разберется. Потому что не должна.
И если у вас будет лежать несколько тегов подряд без общего родителя — это плохой xml, не well formed. Всегда должен быть корневой элемент:
| Нет | Да |
|---|---|
<test> <user>Тест</user> <pass>123</pass> </test> <dev> <user>Антон</user> <pass>123</pass> </dev>Есть элементы «test» и «dev», но они расположены рядом, а корневого, внутри которого все лежит — нету. Это скорее похоже на 2 XML документа | <credential> <test> <user>Тест</user> <pass>123</pass> </test> <dev> <user>Антон</user> <pass>123</pass> </dev> </credential>А вот тут уже есть элемент credential, который является корневым |
Что мы делаем для тестирования этого условия? Правильно, удаляем из нашего запроса корневые теги!
**2. У каждого элемента есть закрывающийся тег
Тут все просто — если тег где-то открылся, он должен где-то закрыться. Хотите сломать? Удалите закрывающийся тег любого элемента.
Но тут стоит заметить, что тег может быть один. Если элемент пустой, мы можем обойтись одним тегом, закрыв его в конце:
<name/>
Это тоже самое, что передать в нем пустое значение
<name></name>
Аналогично сервер может вернуть нам пустое значение тега. Можно попробовать послать пустые поля в Users в методе FullUpdateUser. И в запросе это допустимо (я отправила пустым поле name1), и в ответе SOAP Ui нам именно так и отрисовывает пустые поля.
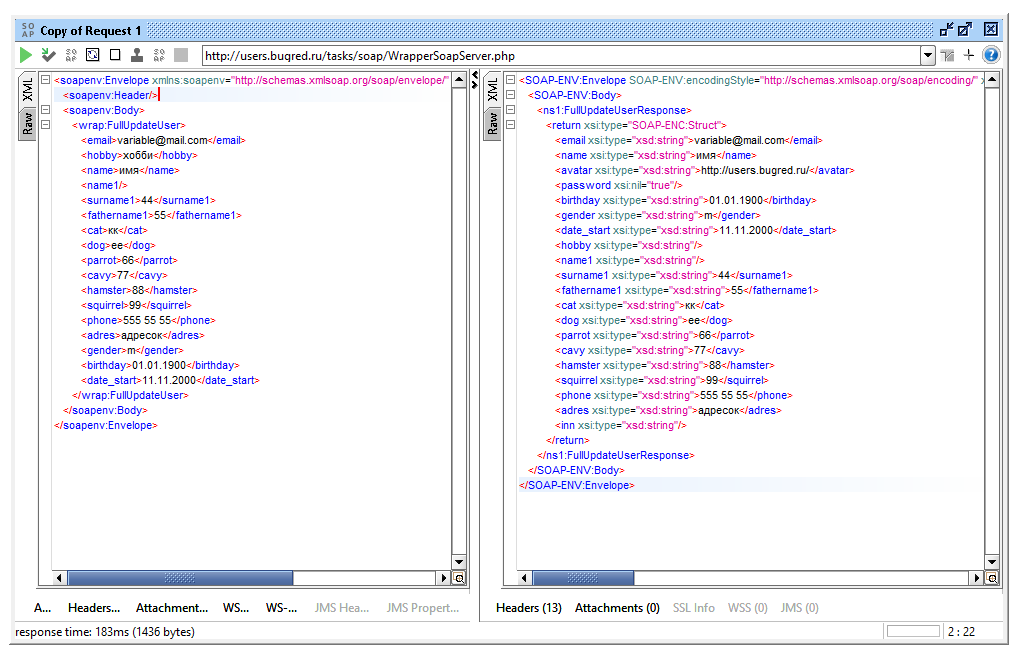
Итого — если есть открывающийся тег, должен быть закрывающийся. Либо это будет один тег со слешом в конце.
Для тестирования удаляем в запросе любой закрывающийся тег.
Для тестирования удаляем в запросе любой закрывающийся тег.
| Нет | Да |
|---|---|
<user>Тест | <user>Тест</user> |
Тест</user> | <user/> |
3. Теги регистрозависимы
Как написали открывающий — также пишем и закрывающий. ТОЧНО ТАК ЖЕ! А не так, как захотелось.
А вот для тестирования меняем регистр одной из частей. Такой XML будет невалидным
| Нет | Да |
|---|---|
<Name>Тест</name> <NAME>Иван</name> <NAME>Тест</name> | <name>Тест</name> |
4. Правильная вложенность элементов
Элементы могут идти друг за другом
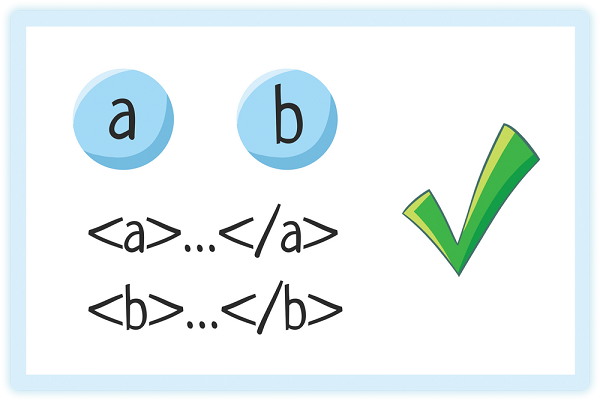
Один элемент может быть вложен в другой

Но накладываться друг на друга элементы НЕ могут!
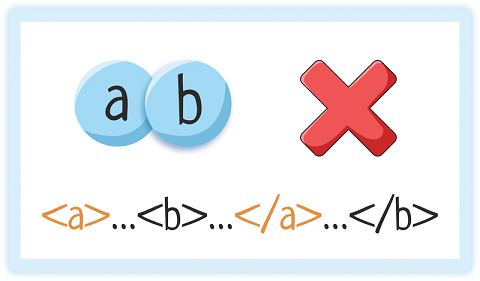
| Нет | Да |
|---|---|
<fio>Иванов <name>Иван</fio> Иванович </name> | <fio>Иванов Иван Иванович</fio> <name>Иван</name> |
<fio>Иванов <b> <name>Иван</name> Иванович</fio></b> | <fio>Иванов <name>Иван</name> Иванович</fio> |
5. Атрибуты оформлены в кавычках
Даже если вы считаете атрибут числом, он будет в кавычках:
<query attr1="123">Виктор Иван</query>
<query attr1="атрибутик" attr2="123" >Виктор Иван</query>
Для тестирования пробуем передать его без кавычек:
<query attr1="123">Виктор Иван</query>
Итого
XML (eXtensible Markup Language) используется для хранения и передачи данных.
Передача данных — это запросы и ответы в API-методах. Если вы отправляете SOAP-запрос, вы априори работаете именно с этим форматом. Потому что SOAP передает данные только в XML. Если вы используете REST, то там возможны варианты — или XML, или JSON.
Хранение данных — это когда XML встречается внутри кода. Его легко понимает как машина, так и человек. В формате XML можно описывать какие-то правила, которые будут применяться к данным, или что-то еще.
Вот пример использования XML в коде open-source проекта folks. Я не знаю, что именно делает JacksonJsonProvider, но могу «прочитать» этот код — есть функционал, который мы будем использовать (featuresToEnable), и есть тот, что нам не нужен(featuresToDisable).
Формат XML подчиняется стандартам. Синтаксически некорректный запрос даже на сервер не уйдет, его еще клиент порежет. Сначала проверка на well formed, потом уже бизнес-логика.